Neural Architecture Search for Improved Transformer Models
Note: I worked on this a while back during an internship at in 2019, when neural architecture search was being productized for finding more efficient transformer based architectures (which had been standardized by then). This blog post is an adapted version of the research that explored early applications of transformer models to e-commerce search problems.
Motivation
With product search being an integral component in e-commerce websites, it is becoming increasingly important to address the product search relevance problem with better accuracy. While relevance models typically depend on ranking the products to obtain better response, one of the often overlooked difficult problems that forms a subtopic of such relevance is removing non-relevant products entirely in response to a query. The challenge lies in the ambiguity that lies in short length queries and with lack of a large dataset. In this work, we address this problem using a defect classification model that attempts to classify a product as being relevant or defect with respect to a query. We build an end to end deep learning model that takes as input the product title and query text and uses multiple layers of representation based off transformer encoder layers to form feature vectors. We try to incorporate multiple loss components in addition to the main cross entropy loss and utilize a reinforcement learning approach to build more complex transformer encoders. Our model leads to a 2% improvement in the F1 score over a deep learning architecture model that only considers cross entropy loss.
Introduction
Product searches in online websites like Amazon, Etsy, Walmart and others have become increasingly popular with the advent of online retail stores. More so, the success of these online stores have been driven by very complex product search algorithms and models that present the most relevant items in response to a customer search query. Traditionally, the search relevance models would be highly dependent on matching text between the query text and the text from the product title from the product catalog. However with the advent of neural network models and large influx of data, it has been possible to adopt methods that typically go beyond text matching and consider the contextual relevance of the product titles and textual content from the query by increasing the model complexity with a large number of layers for representation. These models address the semantic gap that comes with the unstructured format of the query and the product titles and try to locate the commonalities between the query and the product information.
Despite the progress made in such relevance models, one of the key challenges that continue to affect the product searches in e-commerce websites are the defect products that show up in response to the query. The problem is specific to product searches since a product with similar textual content may not be relevant at all to the query, for example consider the case of the query "iphone X 2018" and the product "Commuter Series Case for iPhone Xs" that might be shown in response. Although the product title contains all the relevant words and is contextually similar to the query and so may have a partial relevance score, the fact that it is a case and not a phone makes these kinds of defective responses challenging to identify in absence of any other metadata or impressions data.
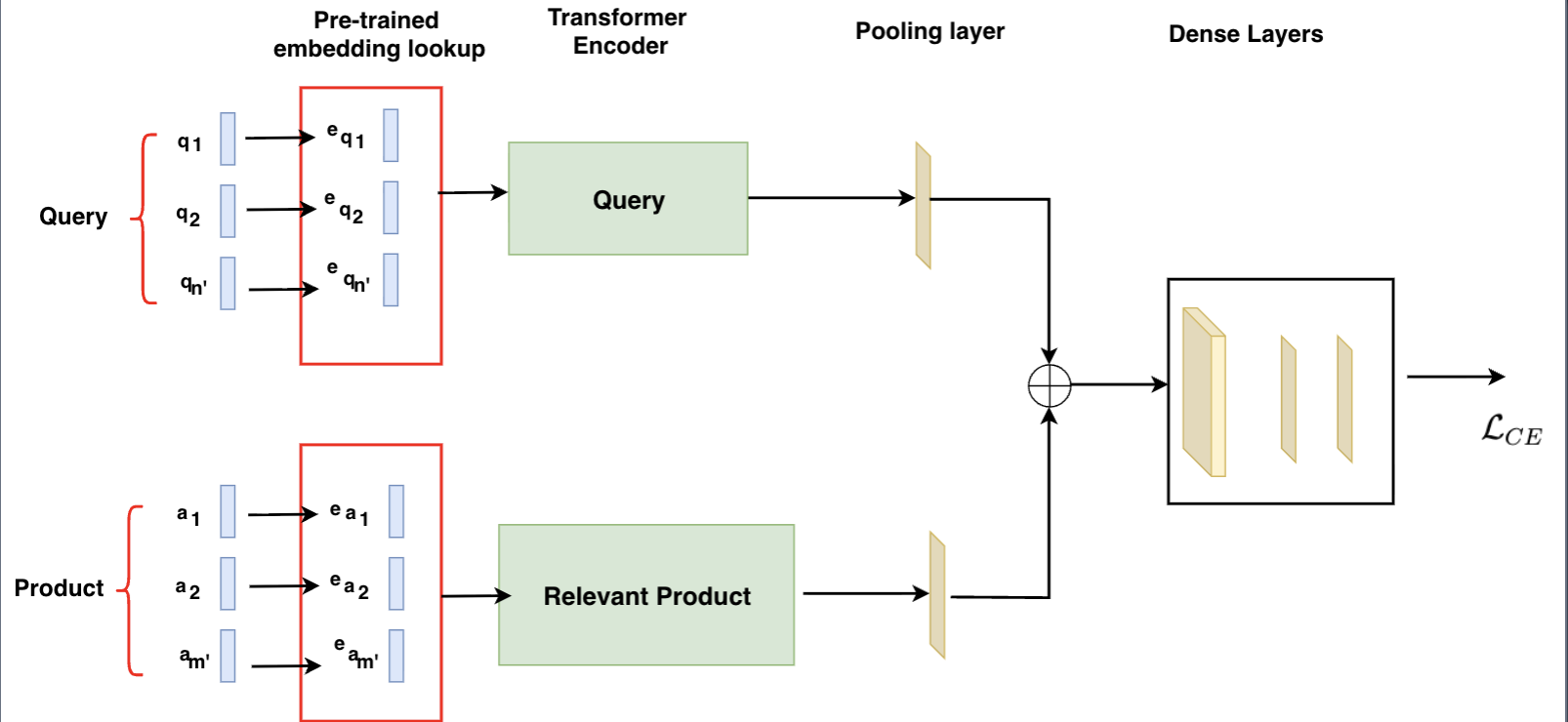
Figure 1a: The base classification model with cross entropy loss based training
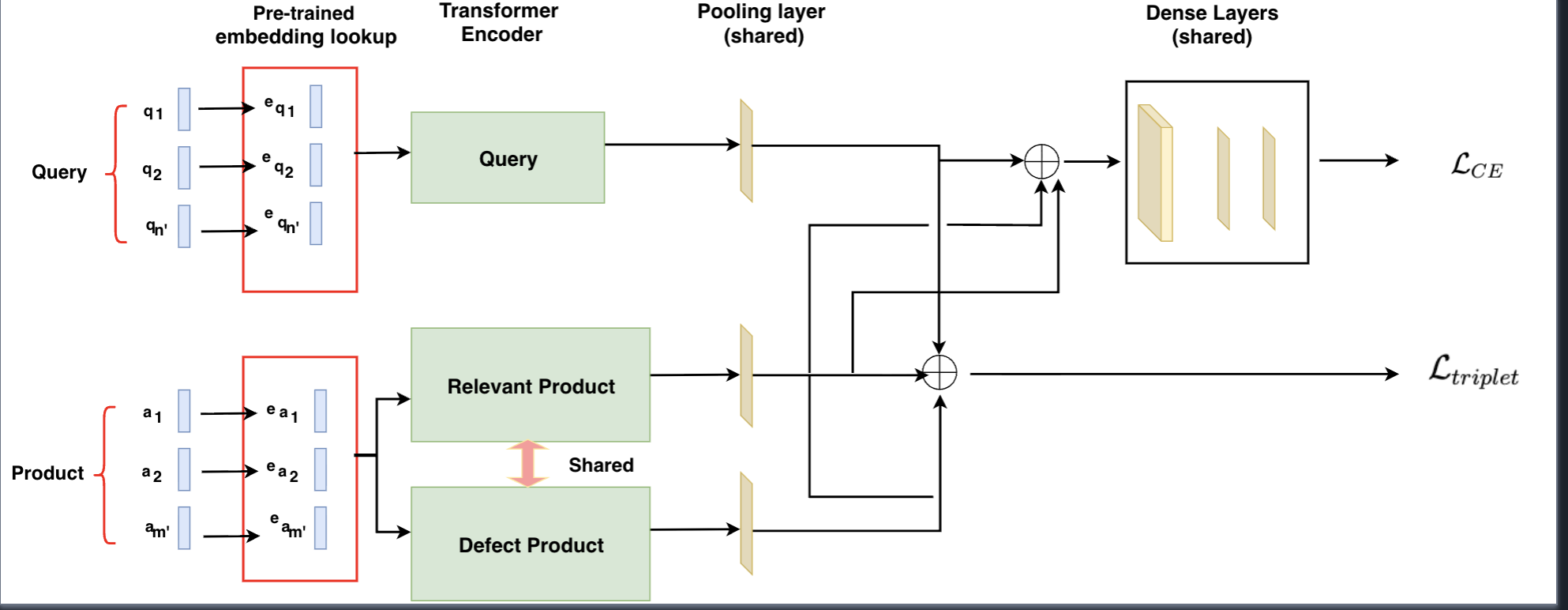
Figure 1b: Learning model weights using only the triplet loss
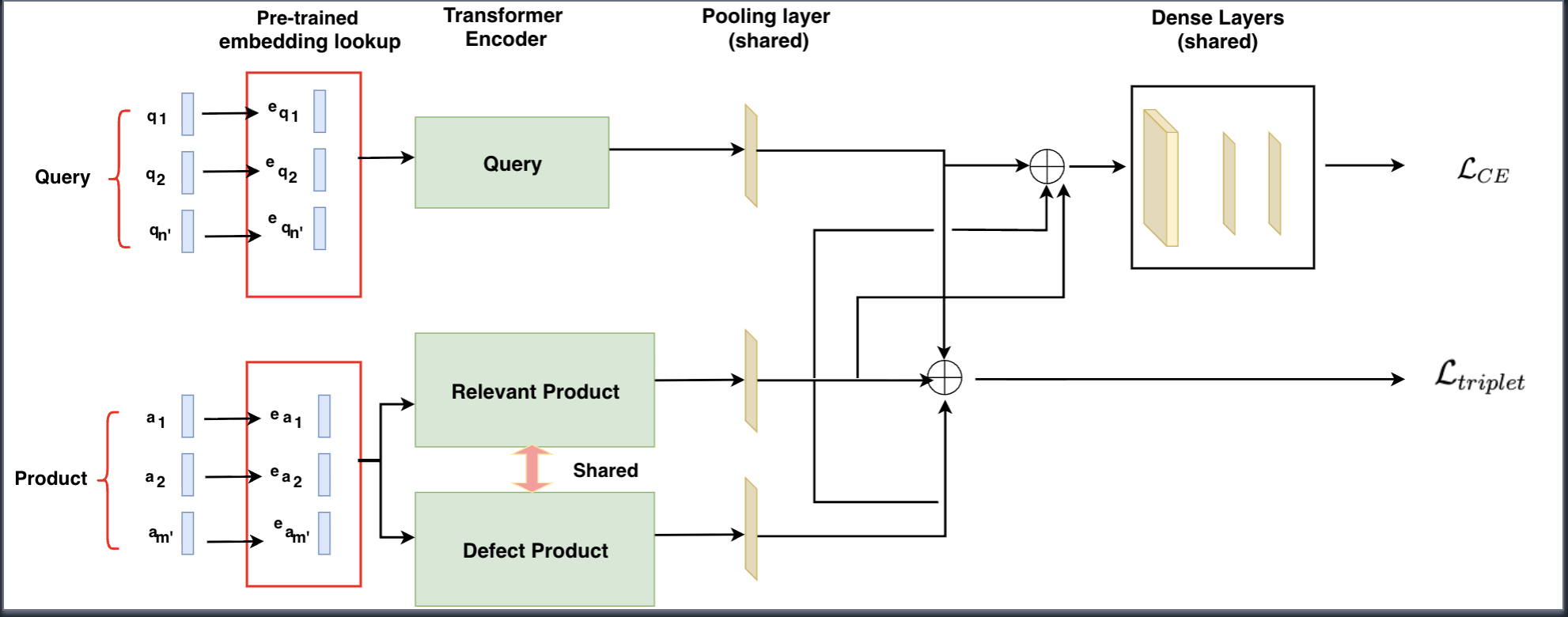
Figure 1c: The classification model with joint loss components
Informally, the defect classification problem in product search aims at classifying a query-product pair as relevant or a defect - it is treated as a binary classification problem where the query-product pair assumes a label 1 if the product is not relevant to the query (defect) and is label 0 otherwise. This is typically different from the traditional search relevance problem since the focus here is on removing the defects more than ranking the relevant products. From this perspective, the challenge is aggravated by the absence of a balanced dataset. A second challenge lies in that we currently address the search defects problem using only the text from the product title and any implicit feedback from sessions searches like clicks or purchases are not used. We use product titles to represent products since merchants tend to put the most informative, representative text such as the brand, name, size, color, material and even target customers in product titles.
Recent deep learning models for query-document relevance computation rely heavily on multiple tensors for computing the contextual relevance between the query and the document text before aggregating them into a final feature vector for computing the relevance score. However, the focus of these methods are not centered on getting better representations of the query or the document itself. We treat our defect classification problem more as a textual entailment problem referring to recent works in question answering where the focus is more towards self attention as well as co-attention encoder based query and document representations. We try to jointly learn a good classification model as well as better representations of the query and the product title itself in an attempt to solve the problem.
Contributions
- We propose a deep learning based end-end model which uses transformer based encoders for classifying a query, product pair as defect or not using the text from the query and the product title exclusively.
- We introduce margin based regularization techniques to obtain better transformer representations of the query and product titles and share our learnings from different techniques to train these models based on multiple loss components.
- In order to get better representations for the product titles, we use reinforcement learning techniques to search for different architectures of the transformer encoder and obtain an improved performance over the traditional transformer based encoder which is held consistent across multiple stacked layers.
Problem Setup
The defect classification problem is defined as follows: Given a query with
Model Overview
The high level basic classification model structure is shown in Figure 1(a) and is very similar to models that address the textual entailment problem for query-answer relevance problem. We start with separate embedding layers for query
Input Embeddings
We use the standard techniques to obtain the word embeddings of each word in a query and the product word sequences. We fix the number of words for each query and each product title to
Encoder Layer
The embeddings output matrices are then fed to layers that output more informed representations of the query and product titles. That is to say, a module that outputs vector representations of the words in the query and product tiles that also incorporate context of the neighboring words in the vector itself. Following several years of research in producing such representations including LSTM based encoders, we use the recent self-attention based transformer modules as encoders. We use the inputs
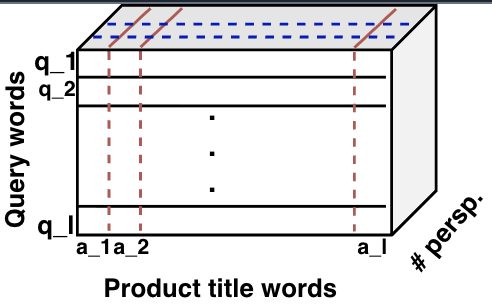
Figure 2: A match tensor that computes the similarity between the query and the product titles among multiple perspectives
Matching Layer
The encoder representations of the query and the product titles do not contain any co-attention mechanism in our architecture, as opposed to a large body of work that incorporate contextual information between the sentences. From our empirical observations, we find that the short query lengths and the unstructured text format of the product titles do not contribute much gains in performance using co-attention mechanisms. As a side experiment, however, we exploit the mutual contextual information from the encoder representations, where given vector representations of two sentences, word-by-word matching augments the attention mechanism.
Formally, the multi-perspective matching function is defined as:
where
where
Pooling Layer
In order to combine the information associated with the query and product encoder outputs with varying sequence lengths, we need to project the vectors to a common latent dimension - we achieve this by learning a self-attention pooling layer that is represented by a weight vector
Interaction Layer
We use an interaction layer from the pooling outputs to aggregate the outputs from the query and product title pooling outputs and the final feature vector used for classification is obtained with by the concatenation operation:
Dense Layer
The interaction vector
Segmenting Defects from Non-Defects Using Margin Based Regularizer
One of the hypothesis we try to test in our approach towards identifying the defects is to be able to segment the defect products from the relevant products in the space spanned by the query for which the identification is being considered. In a margin learning module, the goal is to decrease the distance between the query and the relevant products and increase the distance between the query and the defect products. Since the assumption is that a large volume of query, product pairs data is given, enforcing a small distance between normal and defect product data would tighten the distribution of query to relevant product data in the feature space, thus making the separation of relevant and defect data easy. We use the triplet loss based margin to separate the distances between the query, relevant products and the query, defect products.
Specifically in our case triplet comprise the tuples of the form
where
and the defect product distance is:
Loss Function
For a dataset consisting of pairs
where the triplet loss is defined as:
Here,
Searching for Improved Transformer Representations
Our model of classifying the defects based on separate encoder representations of the product and query text is similar to the question answering textual entailment setup where authors focus on self-attention encoder based representations of the questions and answers to infer their mutual relevance. One of the investigations we pursue in an attempt to improve our performance is to increase the model complexity of the transformer encoders for the query and the product titles.
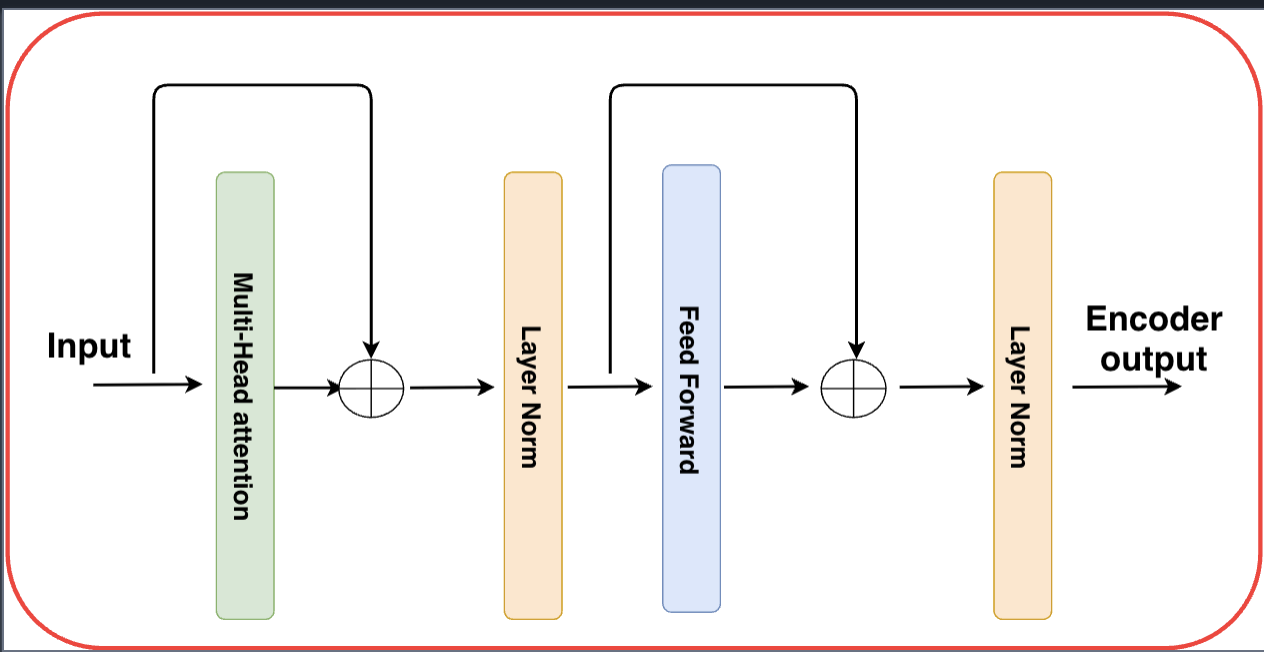
Figure 3: The Transformer encoder cell with multi-head attention and feed-forward layers
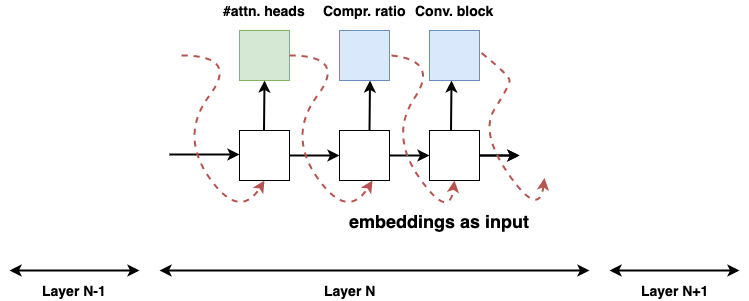
Figure 4: RL based transformer parameter search showing the controller architecture and feedback loop
However, in order to facilitate faster online inference for classifying the query-product pairs as defect or non-defect in production, we cache the encoder representations of the product catalog since the product catalog changes relatively slowly. However, we compute the query encoder representations online and so this allows us the flexibility to experiment with increased model complexity in the product encoder. Following the successes in reinforcement learning based architecture search in deep learning, we focus on the improvement of the transformer block using RL methods.
The reinforcement learning framework helps us in two ways:
- First, it allows us to search for multiple architectures where as opposed to random grid search over an exhaustive possible list of searches, we can guarantee better architectures with fewer searches by incorporating a feedback loop with appropriate rewards.
- In situations where latency in inference needs to be bounded, we can either implicitly incorporate this using a multi-objective reward function or explicitly design agents in the learning framework in order to get architectures that trades-off the improved rewards with the latency in inference.
We manipulate the layers inside the transformer in the following way:
- We search for the number of attention heads among {1, 4, 8}. Additionally we have an option to substitute the multi-head attention mechanism with the Gated Linear Unit (GLU) operation
- We search for the compression ratio of the feedforward layer (ratio of number of hidden units in the feedforward layer to the encoder output dimension), the search space being {4, 8, 16}
- The feedforward layer operation itself can be substituted with 1×1 conv. block, 3×1 depthwise separable convolution and 5×1 depthwise separable convolution
Figure 5: Rewards over the epochs in the RL procedure
An RL controller predicts the action which are the search choices, using which a child model is trained on the classification task. The RL controller is an autoregressive Recurrent Neural Network (RNN) module with one layer with 40 hidden units. The child model is trained using the predicted architecture of the transformer cell and the F1 score on a held-out validation set is taken as the reward. This reward is then used to update the gradients of the RL controller parameters using the REINFORCE policy gradient algorithm:
where the expectation is taken over the policy distribution,
Dataset and Experiments
Note: Specific dataset statistics and marketplace details have been redacted as they contain internal data. The experiments were conducted on e-commerce search data from multiple international marketplaces.
Evaluation Metrics
For our classification model, we use Precision, Recall and F1 score to measure the performance of our model and compare it with the baselines.
Baseline Methods
We compare our classification to the following baselines and model variants:
- LSTM-Encoders: Replace the encoders for both the query and the product with LSTM cells
- Word-by-Word attention: Consider co-attention between the query and product encoders
- GBDT: Use manual features with GBDT models
- BERT pre-trained model: Use a BERT pre-trained model with classification as the target task
- Base DL model with grid search (DL-GS): Train the architecture with hyper-parameters set using a grid search
- Transfer learned model: Two-stage procedure where we first learn weights using only triplet loss, then retrain with classification layer
- Joint Loss DL model (DL-JL): Train with both loss components setting appropriate values of
- DL model with RL based search (DL-RL): Use RL based technique to search for the best set of transformer layers for the product side
- DL model with RL based search with matching layer (DL-RL-ML): Add the matching block to the DL-RL model
Implementation Details
We enforce lower cases on all textual content for both query and products. The upper cap on the word limit for queries are set to
For the base classification model, we used grid search for choosing the number of transformer encoders and set it to 5 for obtaining product representation and 2 for query representations. We use the ADAM optimization technique. We trained each model for 30 epochs with train/test batch sizes set to 1024. Additionally while computing the cross entropy loss, we upweighted the positive samples (the query, product pairs which were defects) by a factor of 10 to account for the imbalance in dataset.
For the RL informed model, we train the RL agent for 200 epochs with a batch size of 1 in each epoch. We then take the top 10 models with the best accuracy and train them from scratch. The rewards over the epochs are shown in Figure 4.
Results
From our experiments, we find that the best results were obtained from the RL informed DL model with specific search parameters for 5 layers that include combinations of different attention heads, compression ratios, and convolutional operations. We obtain a best F1 score of 72.21% that includes the matching layer against the best score of 72.14% without the matching layer. The total number of trainable parameters is approximately 5.1M compared to the base model of 4.9M parameters.
| Model | Precision | Recall | F1 |
|---|---|---|---|
| DL-GS | 73.13 | 67.8 | 70.36 |
| Transfer learned model | 75.1 | 69.2 | 72.04 |
| DL-JL | 74.1 | 69.3 | 71.61 |
| DL-RL | 74.5 | 69.97 | 72.14 |
| DL-RL-ML | 74.65 | 69.92 | 72.21 |
The results suggest that the matching layer or an extra tensor for making associations between the query and the product encoder representations might not be very useful especially when the text is not natural language. Upon further investigation, we find that one of the reasons why the matching layer fails to improve the model significantly can be attributed to the low number of words in a query, often counting to 2 to 3 words.
However we find that in all cases, the triplet loss component helps in improving the performance over the base model with only the cross entropy loss component. This suggests that the loss that tries to separate the defects from the non-defects in the space spanned by the query can be useful in the classification problem. Interestingly, we find that the transfer learned model where we initialize the model with pre-trained weights based on the triplet loss, performs better than the joint loss model with the base architecture, achieving an F1 of 72.04% within 10 epochs.
Loss Calibration
Loss calibration in such multi-loss components is an important component of such models. We found that setting
Table 1: F1 score of the DL-JL model with varying
| Model | |||
|---|---|---|---|
| DL-JL | 69.86 | 70.67 | 71.04 |
Table 2: F1 score of the DL-JL model with varying
| Model | |||
|---|---|---|---|
| DL-JL | 70.35 | 71.61 | 70.12 |