Origins and Design of Neural Scaling Laws
This doc is a hybrid between knowledge gathering (not exhaustive) and the things you keep in your head when building a scaling analysis for a new model family, modality, or data mixture.
- The introduction recaps the Kaplan → Chinchilla formulations and why those particular functional forms show up so often.
- Then I go "backwards from the data" and the architecture: what questions you should ask, what plots to make, and what failure modes tell you the functional form is wrong.
- I mostly ignore the "training dynamics knobs" (batch size, LR schedule, optimizer) except where recent work shows they directly bias scaling fits or compute-optimal conclusions.
Introduction and Notation
The Kaplan-Era Baseline
The 2020 OpenAI scaling paper (often referred to as "Kaplan scaling laws") observed that validation cross-entropy (or log-perplexity) follows clean power laws in (i) model size (parameter count), (ii) dataset size / training tokens, and (iii) training compute — provided the other factors aren't bottlenecking you. It also emphasized that many architectural "shape" details (depth vs width, head count, etc.) matter surprisingly little for upstream LM loss within a reasonable range.
A technical detail that became important later: they define model size using non-embedding parameters because it makes the trend cleaner across depths.
The Kaplan parameterization for the loss function is:
This form is chosen based on three structural principles: (1) it allows rescaling for vocabulary/tokenization changes; (2) as
The Chinchilla Form People Actually Fit Today
The 2022 compute-optimal paper ("Chinchilla") formalizes the now-standard additive parametric scaling ansatz for LM loss:
where
Conceptually, the paper motivates this via a classical "risk decomposition" story:
Two important LLM-era clarifications:
- In LLM training practice,
- If you do care about "unique data vs repeated data," you usually need an additional variable (e.g. repetition factor / epochs / "data density") because the same
Compute Constraint and the Compute-Optimal Frontier
Both the Kaplan-era and Chinchilla-era derivations rely on a compute constraint of the form
for dense Transformers, where
If you minimize
under
The important structure here is: the frontier is where you "balance" the model-limited and data-limited terms.
Also, the statement "power laws are observed only along the compute-optimal frontier" is slightly too strong. What is true is that a single power law in compute
Reconciling Kaplan vs Chinchilla: Why the Coefficients "Moved"
The two papers reach very different conclusions on compute-optimal scaling:
A later line of work argues the Kaplan–Chinchilla discrepancy comes from a mix of:
- parameter counting conventions,
- limited scale coverage,
- training protocol choices like warmup and schedule,
- and optimizer / batch-size tuning.
So the "why" is not a single knob. It is a bundle of measurement choices and training choices, which is exactly the kind of non-universality people forget when they say "scaling laws are universal."
What Actually Justifies the Chinchilla Loss Form
Empirical Regularity Came First
Power-law learning curves predate modern LLMs. Earlier empirical work across translation, language modeling, image, and speech tasks already showed that performance often follows predictable power laws, though the exponents vary by task and domain.
The Kaplan-era paper then made the LLM-scale case: clean power laws across orders of magnitude, some apparent universality, and the idea that these laws are useful precisely because they allow extrapolation and compute allocation.
The Classical Generalization Story Is the Seed of the Functional Form
In classical learning theory, it is common to decompose expected risk into an approximation term (capacity-limited) and an estimation term (finite-sample). In finite-dimensional settings, the estimation error scaling often takes forms like
The Rahimi-style random feature / kernel line of work belongs to this tradition. With
The mismatch with deep nets is obvious: the exponents empirically are often not locked to
Why "Power Law + Constant" Is Natural in Cross-Entropy
In autoregressive modeling, cross-entropy has a clean information-theoretic interpretation as an entropy term plus a KL divergence from the true distribution to the model distribution.
A complementary way to say the same thing is: language modeling is compression. The compression viewpoint connects prediction loss, codelength, and scaling phenomena, and it is also a practical lens for reasoning about tokenization, modalities, and why "loss floors" are distribution-dependent.
Theory Attempts: Variance-Limited vs Resolution-Limited Regimes
Two theory threads are worth separating.
Variance-Limited Regime
In the limit of infinite data or an arbitrarily wide model, some aspects of neural network training simplify. If we fix one of
Resolution-Limited Regime
This is the regime closer to the Chinchilla form. If one of
with
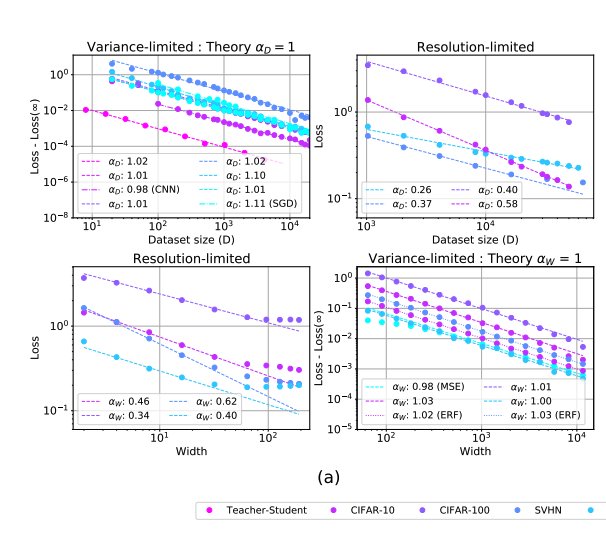
Empirical verification of variance-limited (exponent ≈ 1) and resolution-limited (exponent ≈ 0.26–0.62) regimes across Teacher-Student, CIFAR-10, CIFAR-100, and SVHN datasets.
Implications
This means that the Chinchilla coefficients broadly align with theoretical predictions in these one-dimensional infinite-limit settings.
But the major limitation remains: joint scaling in
Additionally, the assumptions behind the clean theory — local smoothness, effective convexity, manifold regularity — are not guaranteed in real deep networks. So in the real world, theoretical predictions for scaling coefficients are often unreliable, because quantities like the data manifold dimension are not known a priori.
Teacher–Student and Data Manifold Dimension
This is where scaling-law work becomes more physically interpretable.
The Sharma–Kaplan Dimension → Exponent Bridge
One influential idea (Sharma & Kaplan) is that scaling exponents can be explained by the intrinsic dimension of the data manifold. In that view, if neural models are effectively performing regression on a data manifold of intrinsic dimension
for cross-entropy and MSE losses.
This is interesting because it gives a "physical property" interpretation of the exponent: the exponent behaves like a critical exponent controlled by an effective dimension of the learning problem, not just by the fact that we are using Transformers.
Why Teacher–Student Matters
The teacher–student setup is useful because it gives a controlled environment where:
- you can dial the teacher complexity,
- you can vary the intrinsic dimension,
- you can separate realizable vs non-realizable structure,
- and you can measure how the fitted exponents move.
The point is not that teacher–student models are realistic LLMs. The point is that they let us identify what kind of hidden structure could generate the empirical exponents we later observe in real data.
A practical implication is that if you are building a scaling law for a new modality, it can be useful to first design synthetic teacher–student controls or procedural datasets to understand how geometry and complexity change exponents.
Compression, Zipf/Heaps, and Why
The compression-based perspective suggests a sharper interpretation of the irreducible term:
- Meanwhile the exponents and prefactors carry information about geometry, compressibility, and statistical complexity.
So the scaling-law coefficients are not merely fit parameters. They are often fingerprints of distributional structure plus training protocol.
Constructing Scaling Forms Beyond Dense-Text Transformers
Q1. Is Power Law Universal?
Empirically, power laws show up a lot, but "universal" is too strong. There are several concrete ways this fails.
- Non-power-law transient regimes — Early training or small-data regions can look linear-ish or saturating before entering an asymptotic power-law regime.
- Regime changes / bends / inflections — Broken or smoothly-broken power laws can be needed when multiple mechanisms are active.
- Data selection changes the law — Better data pruning or curriculum can alter the apparent scaling with data size.
Vision Example: Why a Strict Power-Law Estimator Can Fail
One useful example from vision scaling laws is the distinction between fitting for interpolation vs fitting for extrapolation.
A common estimator is:
This works if the observed points already lie in the asymptotic power-law regime. But when the data are not yet in that regime, a more flexible family is needed. One such corrected form is:
which reduces to the simpler saturating power law when
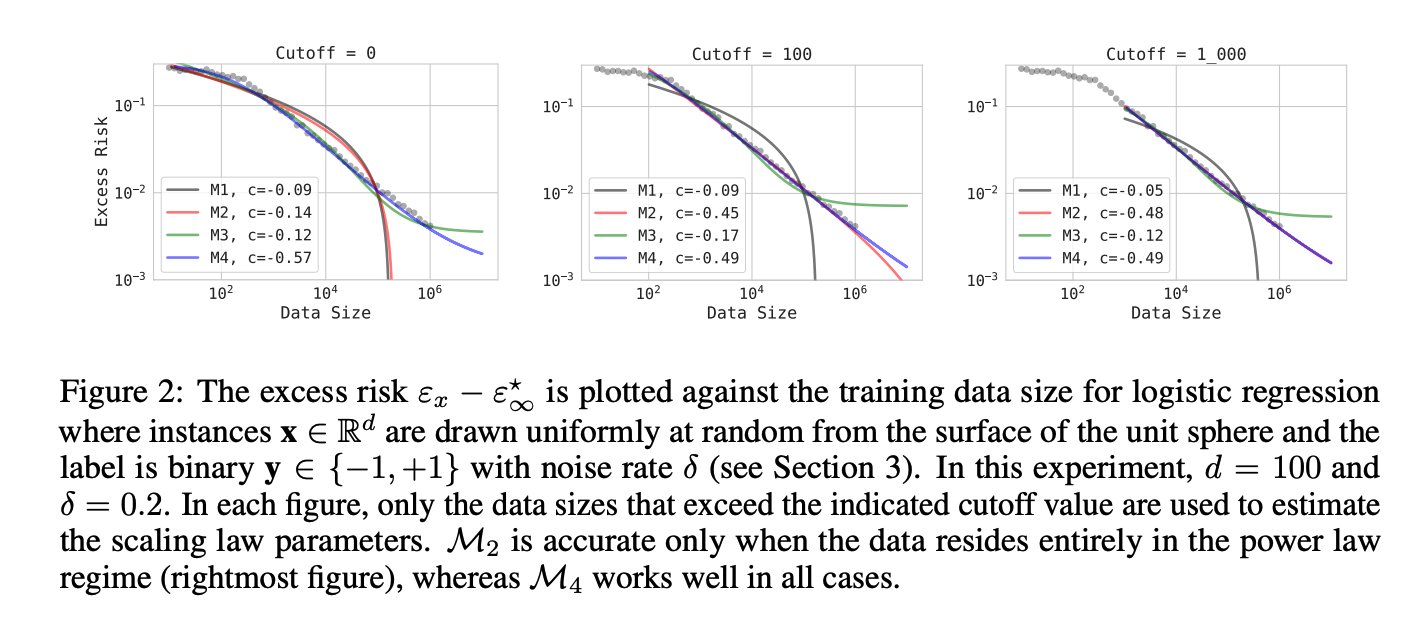
The excess risk
The point is not that the power law is "wrong"; it is that a pure power law can fail if your observed regime is transitional.
Example: Exponential Law in Sparsity
In sparse-model work, one axis can empirically look exponential while another looks power-law. A representative form is:
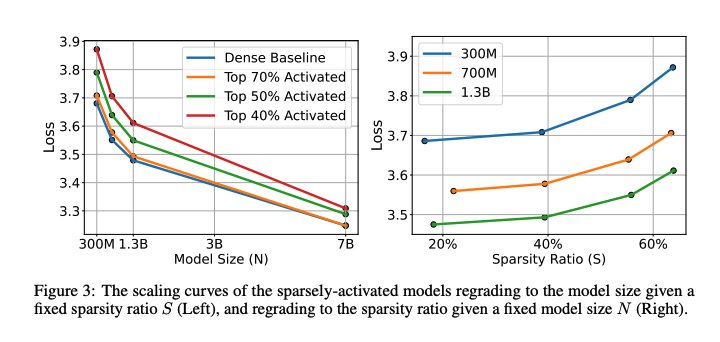
Left: scaling curves of sparsely-activated models vs. model size N at fixed sparsity ratio S. Right: loss vs. sparsity ratio at fixed N. Note the exponential behavior along the sparsity axis.
This is a good design pattern: if one dimension empirically looks exponential, do not force it into an additive
Q2. Are
For dense text-only models, people often treat "size" as parameter count and ignore shape, because upstream LM loss depends weakly on depth/width at fixed scale.
But this breaks quickly outside that setting.
- In vision, compute-optimal performance can depend strongly on shape dimensions such as depth and width, and the compute-constrained loss can be quasiconvex in those axes.
- In routed / MoE models, "model size" splits into total parameters vs active parameters per token vs routing structure.
- In sparse / pruned models, sparsity ratio
Example: Vision Transformer Scaling
For vision transformers, the loss estimator proposed in Zhai et al. takes the form:
When compute
So the answer is: no.
Q3. When to Include Interaction Terms?
The theory side does not provide guidance on when scaling coefficients couple across dimensions. The most practical recipe is:
- Fit a separable form first.
- Slice the data along one axis.
- Check whether the fitted coefficients drift systematically with another axis.
If they do, your form is missing an interaction term.
Example 1: Routed / MoE Models
For routed models (Clark et al.), the first proposed scaling form is separable:
However, when fitting this form separately at each model size, the slope
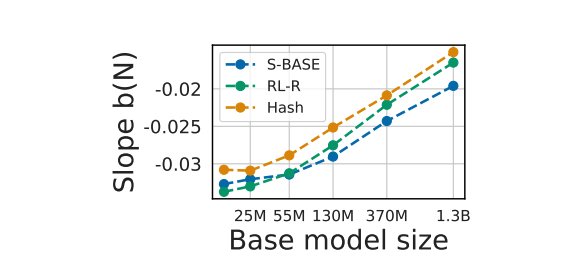
The slope b(N) — the marginal benefit of adding more experts — is not constant; it grows (in magnitude) with base model size. This is the diagnostic for a missing interaction term.
The authors therefore propose the corrected form with an interaction term:
In log-space, multiplicative interactions are often the cheapest way to let one slope depend on another axis.
Example 2: Sparse Language Models (Frantar et al.)
When studying scaling laws for sparsely-connected foundation models, the sparse form needs to capture interaction between sparsity ratio
Visualizing the T5/C4 sweep results across all sizes and sparsity levels confirms the parallel structure:
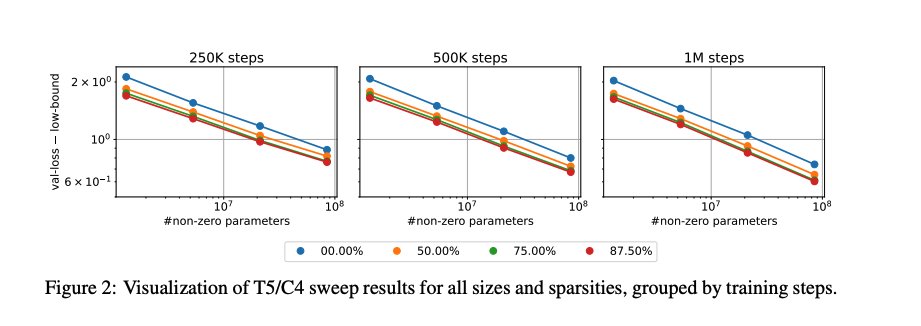
Validation loss minus lower bound vs. number of non-zero parameters, grouped by training steps (250K, 500K, 1M). Loss vs. non-zero parameter curves for different sparsity levels form near-parallel lines — indicating that sparsity primarily shifts the A(S) prefactor.
Example 3: Alternative Sparse Form
A closely related form (from a different sparse LM paper) captures the sparsity dependence differently:
where
Q4. Can We Have Multiple Scaling Forms for the Same Loss / Data Distribution?
Yes. There are usually several plausible forms to try:
- additive vs multiplicative,
- independent vs interacting,
- power-law vs exponential,
- single-regime vs broken-regime.
Several papers find that multiple fits can be similarly good in raw predictive accuracy. Then interpretability and parameter efficiency become real selection criteria.
A useful researcher mindset is that a scaling law is not just a fit. It is an extrapolator you trust under constraints.
Example 1: Scaling with Repeated Data
The scaling analysis for training with repeated data (Muennighoff et al.) compares multiple parametric fits. Chinchilla-style forms with no modification to account for data repetition have poor
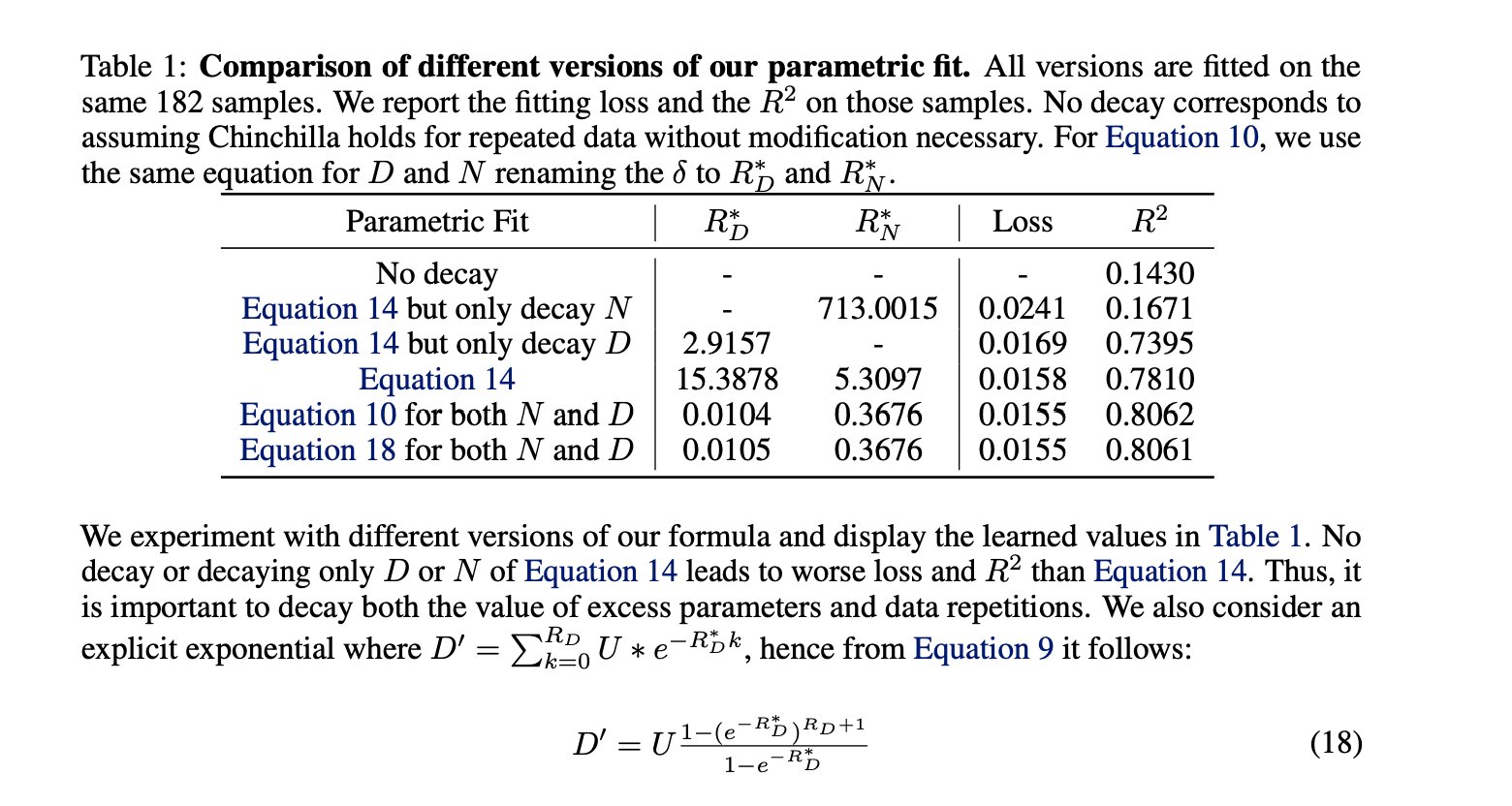
Table comparing different parametric fits. Forms that decay both the excess parameters and data repetitions (Equations 14, 10, 18) achieve R² > 0.80, whereas no-decay or single-axis decay forms are significantly worse.
This illustrates why it is important to introduce repetition explicitly into the law rather than absorbing it silently into
Example 2: Data-Dependent Scaling Laws via Compressibility
The gzip data-dependent scaling law uses a two-step approach. First, define a compressibility score for each dataset:
Then, fit the Chinchilla form separately for each dataset to obtain coefficients
The final data-dependent scaling form is then:
A Practical Workflow for How Researchers Actually Come Up with Scaling Laws
This is the engineering reality.
Pick the metric and regime — Upstream next-token cross-entropy is often preferred because it is smooth and information-theoretically interpretable.
Define the axes precisely — What does
Design the experiment grid around the question — If the question is compute-optimality, isoFLOP profiles and training-curve envelopes are central. If the question is shape-optimality, you need deliberate shape sweeps. If the question is sparsity, you need slices at different sparsity levels and training durations.
Fit for extrapolation, not just interpolation — A form that interpolates beautifully can extrapolate badly. Held-out extrapolation checks matter.
Look at coefficient drift — This is often the most informative diagnostic. If a "constant" changes systematically with another axis, your law is missing structure.
Where Scaling-Law Fits Go Wrong in Practice
A scaling-law project can fail because of things that look mundane:
- schedule mismatch, especially when comparing models trained for different token budgets,
- warmup effects,
- optimizer / batch-size retuning across scales,
- parameter-counting conventions,
- data mixture changes,
- tokenizer differences,
- or simply fitting outside the asymptotic regime.
This is why it is better to think of a scaling law as a measurement protocol plus a functional family, not just an equation.
Off-Frontier Training and the LLM Reality Check
Overtraining Smaller Models Is a Scaling Axis in Its Own Right
A lot of real LLM practice does not live exactly on the Chinchilla frontier. Often we deliberately overtrain smaller models for more tokens to reduce inference cost.
This means the tokens-to-parameters ratio itself becomes a scaling variable of interest. In that setting, "compute-optimal" is not the only frontier that matters.
Repeated Data: When More Tokens Stop Meaning More Information
Once repeated data enters the picture, the mapping from "tokens processed" to "novel information acquired" bends.
So while Chinchilla-style
- you introduce repetition explicitly into the law,
- or you accept that the effective data-scaling will bend or saturate.
Downstream Emergence and the Limit of Extrapolating from Loss
Another important LLM-era caution is that downstream metrics may show thresholds, inflections, or artifacts that do not inherit the smoothness of cross-entropy.
So if your real question is about downstream task performance, you should be careful about assuming that a clean upstream loss law transfers directly.
Final Takeaways
- The Chinchilla form is best understood as a structured empirical ansatz, not a theorem.
- The coefficients of a scaling law are often not arbitrary; they can reflect data geometry, compressibility, intrinsic dimension, and protocol choices.
- The hardest and most important part of scaling-law work is usually choosing the right variables and the right experimental slices, not fitting the equation afterward.
- Interaction terms should be added only after the data show you that separability fails.
- Teacher–student settings, manifold-dimension arguments, and compression views are useful because they give a more "physical" interpretation of what the exponents might mean.
- For LLMs, tokens processed, unique data, repeated data, data quality, and mixture composition are all distinct notions. Treating them as one variable can bias the fit.
- A good scaling law is not just a curve fit. It is a reliable extrapolator for decision-making.
References
- Kaplan et al., Scaling Laws for Neural Language Models.
- Hoffmann et al., Training Compute-Optimal Large Language Models (Chinchilla).
- Pearce et al., Reconciling Kaplan and Chinchilla Scaling Laws.
- Sharma and Kaplan, A Neural Scaling Law from the Dimension of the Data Manifold.
- Hutter, Learning Curve Theory.
- Bahri et al., Explaining Neural Scaling Laws.
- Alabdulmohsin et al., Revisiting Neural Scaling Laws in Language and Vision.
- Alabdulmohsin et al., Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design.
- Clark et al., Unified Scaling Laws for Routed Language Models.
- Frantar et al., Scaling Laws for Sparsely-Connected Foundation Models.
- Muennighoff et al., Scaling Data-Constrained Language Models.
- Zhai et al., Scaling Vision Transformers.