Efficient continual pre-training of LLMs
I have been working on this topic on and off for some time now. While continual learning has been a subject of research for many decades now, I have been frustrated to see that most of these techniques cannot be adapted easily when pretraining language models on billions of tokens due to costly optimization procedure. So far, I haven't been able to materialize my research into any fruitful publication. Therefore, I decided to give a shot at trying to formulate the continual learning problem and propose few directions of research. This blog post will continue evolving over the next few weeks.
The objective of continual learning (CL) is to accumulate knowledge on non-stationary data or from a stream of non i.i.d. samples. Here I would discuss some methods that can be systematically applied for continual pretraining of LLMs. But CL for Large Language Models (LLM) is known to be limiting in its implementation in two scenarios: (1) the data for previous domains/tasks are assumed to be too large to start pretraining with all data from scratch (2) catastrophic forgetting of past information leading to the memorization vs generalization issue in pre trained language models. In that regard, there are two aspects of CL to focus on:
1. Backward Transfer: which is the influence that learning on a new domain has on the performance on downstream tasks of domains on which the LLMs were previously pretrained on. Positive backward transfer exists when learning about some domain increases the performance on tasks on some previously used domain. The opposite negative transfer is catastrophic forgetting.
2. Forward transfer: which is the influence that learning on a new domain has on the performance on downstream
tasks of domains on which the LLMs will be pretrained on, in future. This is the aspect of transfer learning or generalization that has been known to be an advantage of pre-trained LLMs.
One of the utilities of CL for LLMs is in developing a more principled approach to adaptive data selection strategies for sampling the replay buffer for CL as a sequential sampling problem or as a constrained optimization problem with speedup on large datasets and model sizes as well as for being better geared towards mitigating negative backward transfer. In that sense, there are many abstractions of the problem that can be formulated. Here, I provide a few forms of abstraction.
Abstraction I
Formally, we have a language model
Abstraction II
A different variant of this CL setup would be to select a subset
Yet a different variation of the learning problem can be as follows: we have a language model
Abstraction III
A tangential direction to handling the CL process is as follows: given a model with parameters
A hard constrained continual learning would also entail constraints on the latency of the methods to enable a tradeoff between performance and time taken to adapt these models fast (
Note: The following sections were initially drafted in 2023 as part of my exploration into continual pre-training methods. While some aspects may seem dated given the rapid progress in LLM research, the core principles and methodological approaches remain relevant.
Desiderata for the Problem
The problem statement defined in this proposal is close to multi-task pretraining with adaptive data selection and we want to improve on the sampling technique for data from different tasks while training.
Having defined the above abstractions, we lay out a few desiderata of the problem that applies to all of these abstractions:
We want to minimize negative backward transfer on downstream tasks related to
We want to avoid techniques like online batch selection during the CL process that solves a subset selection optimization problem for each mini-batch in an SGD optimization. This would not be feasible in terms of computation for large models and large data.
We want to avoid techniques like network expansion where possible, since these are often hard to adapt especially when we work with partner teams who have model size restrictions and specific model types to use. Also, most teams will have their own adapters for parameter-efficient finetuning so, adding our own adapters or prefixes like soft-prompts in the pre-training/pre-finetuning stage increases the complexity unless we have shared modeling plans across the teams.
What are Alternative CL Methods to Rehearsal?
Some details on methods alternative to rehearsal like generative replay, EWC have been listed in this review: Continually pretraining Multilingual LMs to alleviate forgetting. A different branch of work includes network expansion like adapters for domain specific finetuning, for example DEMIX Layers: Disentangling Domains for Modular Language Modeling which proposes mixture-of-experts to route specific FFN layers for specific domains and the recent work on Branch-Train-Merge, but these are parallel to rehearsal and could be taken up as a separate research direction for continual learning.
Evaluation Criteria
For each dataset
Protocols for Learning
1. Single-Pass through All Data (Streaming)
Consider two streams of tasks, described by the following ordered sequences of datasets:
2. Many Passes over All Data (Offline)
It is borrowed from supervised learning - during training the learner does as many passes over the data of each task
In this work we follow the second paradigm where we assume that the dataset
Baselines/Existing Work
What is the Simplest Baseline?
Given two sequential tasks A and B, there are two intuitive ways of training: (1) train on A and then train on B which will lead to forgetting the knowledge of A and then (2) train on A and then train on B but while regularizing using L2 norm. The below methods from well cited papers are some baseline experiments which I am exploring for a start.
B1. Mix-review
In this work called Mix-review strategy, for each finetuning epoch, we mix the target data with a random subset
It can be paired with an additional L2 regularization toward the pretrained parameters
The simpler version of this is to keep mix-ratio to 1, but only use the loss
B2. Logit Distillation
Methods like Dark Experience Replay alleviate forgetting by matching the network logits across a sequence of tasks during the optimization trajectory, formulated as below:
where
This method can be naturally extended to representation distillation where instead of matching the logits, match the layer parameters like the embedding layer or the last layer.
B3. Train on the Entire Data
The goal is to start fresh pretraining on the entire dataset
B4. Elastic Weight Consolidation
This used to be a very popular method for online/sequential continual learning and is an improved version of an L2 regularization but one that uses replay buffer. It is in a way a form of selective parameter updates as opposed to data selection we are proposing. Empirically, it has been observed that L2 regularization leads to degradation. EWC is a technique that updates the parameters when training on B while "selectively" adjusting the parameters that are important to A. Using the Fisher information from task A (which is where we use the replay buffer) denoted by
This method is pretty neat, but it can take some computation overhead while computing the Fisher information on
Proposed Methods/Experiments
The goal here is straightforward: we want/have to sample points from
E1: Probability Distributions for Sampling
Examples are sampled according to a multinomial distribution with probabilities
The main disadvantage of this method is that the data selection is not tied to the optimization. So when we perform multiple rounds (like CL on the same model every 6 months) of continual learning on the same model, we may be using the same set of samples for every round which can at some point lead to overfitting. One way to alleviate this is to use an explore-exploit scenario so as to mix samples.
E2: Sequential (re)sampling of Memory Buffer
E3: Curriculum Learning for Adaptive Replay
E4: Select cR Examples from D and Use Dynamic Sampling
We adopt a hybrid between online optimization and offline sampling like E1. For the first epoch, train the model with
Before delving into the proposed experiments, we list down the existing approaches on adaptive data selection on which this work is based on. Adaptive data selection methods often do the data selection every
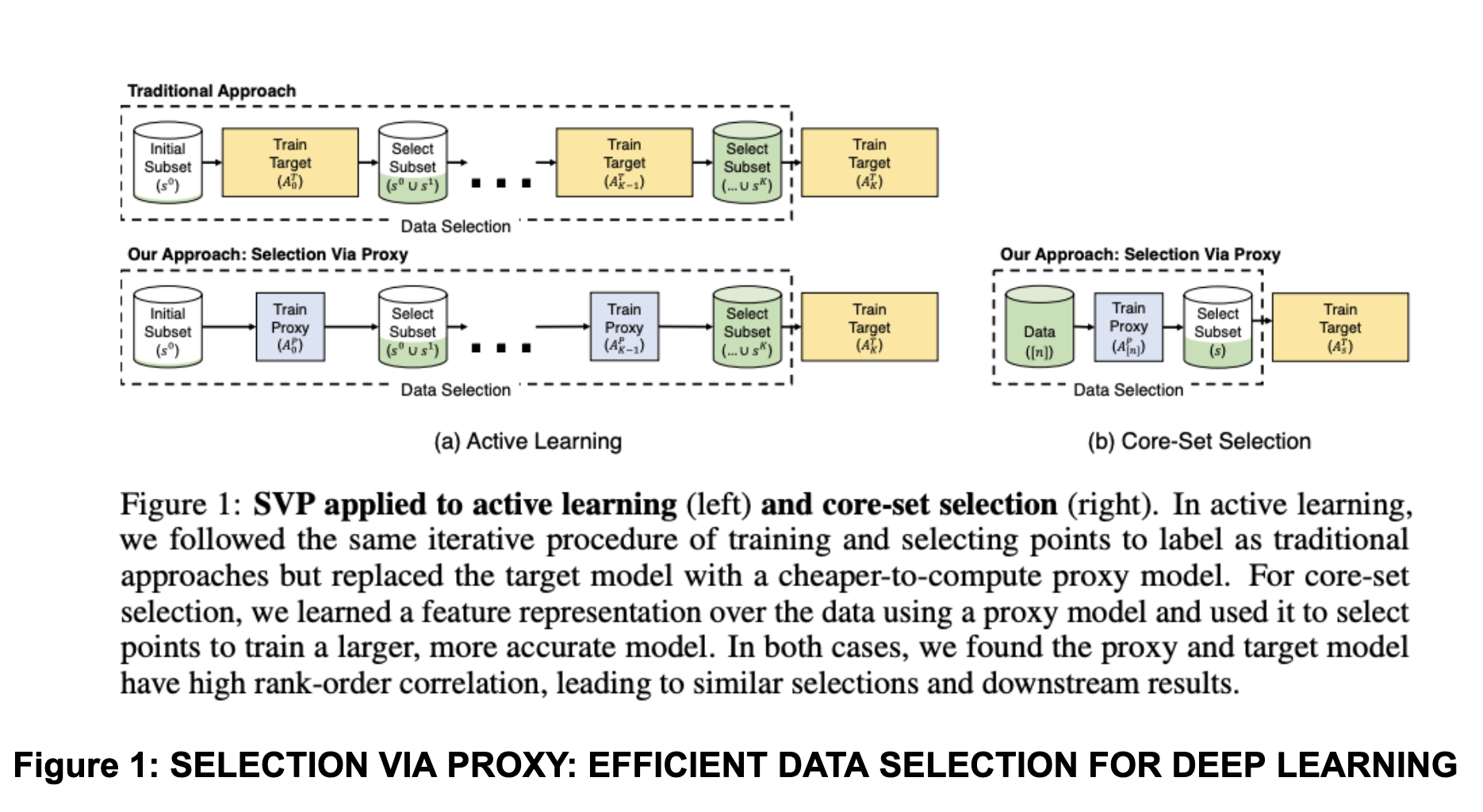
Figure 1: Selection via Proxy - efficient data selection approach
The general philosophy of these data selection methods is based on coreset selections. Coresets are small and informative weighted data subsets that approximate original data in terms of some defined objective/metric (in our case, the distance between gradients). Several works have studied coresets for efficient training of deep learning models in the supervised learning scenarios. Although they have never been considered to be much in favor of training the models on full data for several days, these techniques seem relevant to our problem where we are necessitated to select a subset of data from
The routine steps for such data selection methods are as follows:
Define an error function that you would want to use for selecting the points (these are standard gradient based errors). Here, selection means selecting a subset of the rehearsal data with weights every epoch or selecting a set of mini-batches in each epoch. An optimization algorithm will be able to select the data for you along with the weights. So the question boils down to the way you define the constraints to define the optimization objective and how the technique computes the associated weights.
Use some approximations to compute the gradients more efficiently like considering only last layer gradients and upper bounding gradient norm differences.
Solve the optimization problem such that we get
Most of these methods are theoretically well studied in the context of convex functions where they assume Lipschitz continuity and smoothness to arrive at convergence rates and upper bound the errors. For our work, we mainly adapt these to our non-convex objective functions.
Why Cast Replay Buffer Selection as an Optimization Problem?
Most work on rehearsal till now have shown that rehearsal with random/proportional sampling works quite well, but they do not focus on situations where we need multiple rounds of CL (updates) on the same model. Simple rehearsal methods may end up repeating the same samples over the rounds, however, the logic behind sampling a fixed set of points for each
Why Run First Epoch on All
Warmstarting with large buffer has been known to help in many cases, in addition, we may want to do some importance sampling in the beginning and add some heuristics based on that for later sampling.
E2.1 GRAD-MATCH

Figure 2: Procedure in GRAD-MATCH
The data selection optimization problem every
The norm is the L2 norm and the error is self-explanatory, difference between the gradient on all data points and the weighted coreset. We use norm of the gradient differences as the value since the goal is to approximate the full gradient with the coreset. These optimizations are solved using Orthogonal Matching Pursuit (OMP) algorithm (which are already included in many libraries) and are typically used to compute a greedy approximation to the solution of sparse coding problems in signal processing.
N.B. Since one of the steps of OMP include inverting the gradient matrix, we can do some approximations using Cholesky decomposition to speed the methods here. We also plan to do distributed greedy approximations across nodes in a map-reduce fashion so as to speed up the algorithm.
One of the key steps here is to achieve distributed computation of the signal recovery problem similar to distributed matrix factorization for speedups. For the 1st iteration of the experiments, we will consider separate optimizations and data selection for each node and there will be no communication between the nodes to reach a global solution to (4). Based on the experimental results, we may look into federated continual learning with inter-node communication for global optimization.
E2.2 Gradient Based Coreset Selection
Balles et al. 2022 extends the above approach to a more constrained setup in continual learning where we do not need the weights
subject to the cardinality constraint
Approximations to speed up the method:
They project the embeddings
They use the last layer gradients when computing the gradients which is also a popular approximation adopted in many papers including GRAD-MATCH.
In my opinion, for large
E2.3 CRAIG (Coreset Selection)
The optimization problem of CRAIG is as follows:
This optimization problem is particularly difficult to solve and they simplify it to:
where (6) is an upperbound to (5). It is still NP-Hard to solve it. The steps to solve this is:
Use a submodular function to approximate
Once the subset (coreset) is selected, the weights are defined by the nearest points (similar to k-medoids) in the entire data to these coresets.
The main drawback with this approach is the greedy submodular algorithm for selecting the coreset. It is expensive for coreset selections among millions of points.
E2.4 Our Method v1
Since most of these methods are not adapted to continual learning, the data selection through optimization is separate from the training process. We want to select the subset
subject to the cardinality constraint
Some considerations:
Mini-batch subsets - since we generally consider points in the context of mini-batches, the problem can reformulated as selecting mini-batches among a set of mini-batches instead of single points in an epoch. This will speed up the gradient computations by a factor.
Multi-node computations - Since we use multi-node sharding of pretraining data, the speedup can also come from more efficient techniques to shard the data offline based on importance sampling.
E2.5 Our Method v2
As mentioned in the problem statement, since our data has
E2.6 Our Method v3
This is similar to meta-learning where the model is trying to jointly learn which examples to pick and learn how to update the model parameters following that. A different method would be to do a bi-level optimization similar to the approach used in Safe Deep Semi-Supervised Learning for Unseen-Class Unlabeled Data. We can do a one step gradient optimization of the network considering
The inner level optimization is only run for 1 gradient step on the entire pretraining corpus. This requires solving a discrete optimization for the outer level problem. This will be explored as a separate research problem.
Speeding up the Optimization in Eq. 7
The goal is to carry out importance sampling with distributed training as an independent step similar to techniques used in variance reduction techniques for SGD - Not All Samples Are Created Equal: Deep Learning with Importance Sampling. One example from Variance Reduction in SGD by Distributed Importance Sampling provides relevant techniques.